Group Assignment
Table of contents
In the tutorial and individual assignments, you have learned the background of the Smell Pittsburgh application and the machine learning pipeline to build a model to predict the presence of bad smell based on sensor and weather data. In this group assignment, you will conduct more experiments to investigate the pipeline, as described below:
| Design brief. |
| Local citizens in Pittsburgh are organizing communities to advocate for changes in air pollution regulations. Their goal is to investigate the air pollution patterns in the city to understand the potential sources related to the bad odor. The communities rely on the Smell Pittsburgh application (as indicated in the figure below) to collect smell reports from citizens that live in the Pittsburgh region. Also, there are air quality and weather monitoring stations in the Pittsburgh city region that provide sensor measurements, including common air pollutants and wind information. |
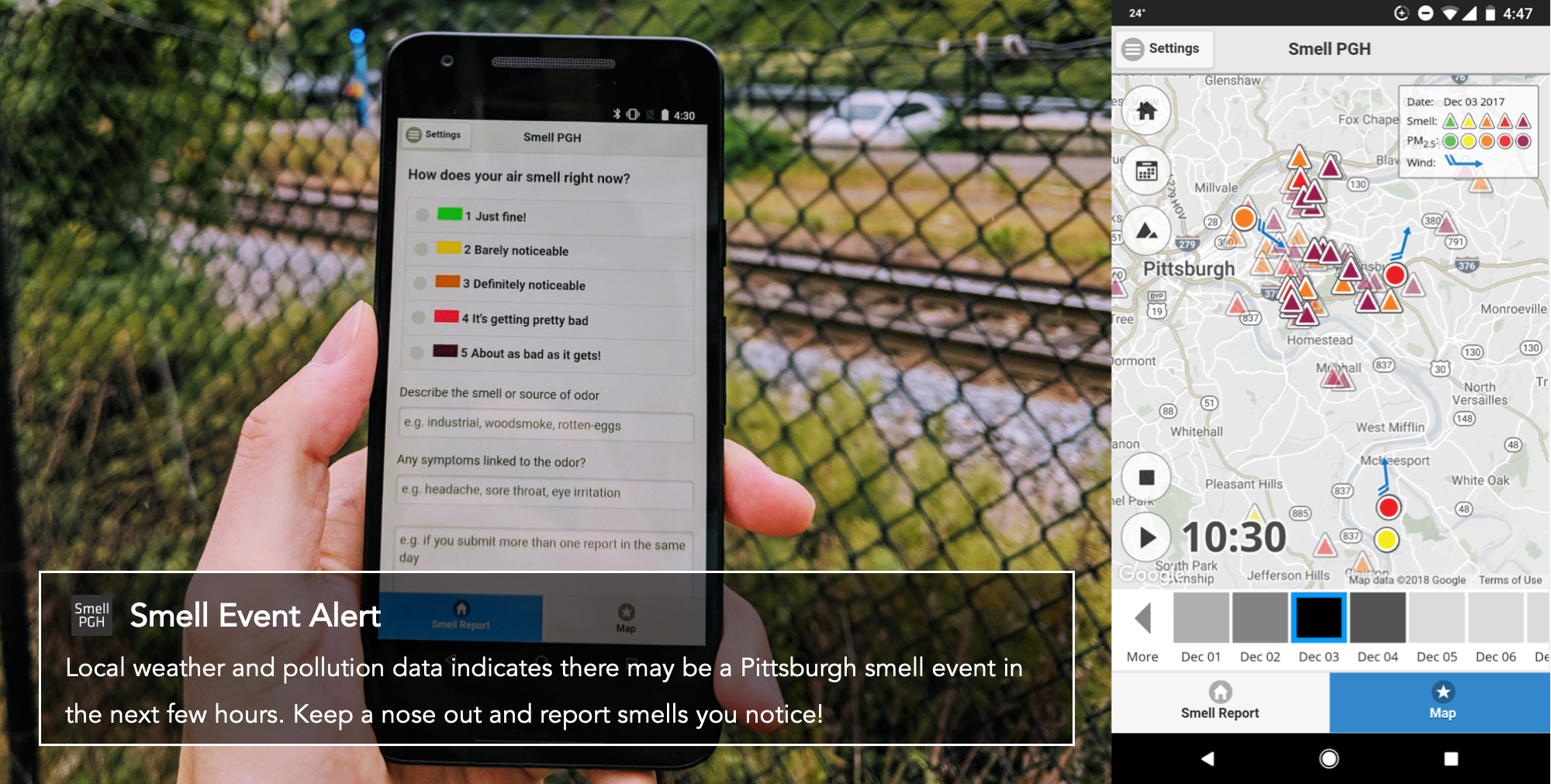 |
| Machine learning scientists have developed several models that can be suitable to map the sensor data to bad smell events. However, the scientists who develop the model do not have sufficient domain and local knowledge to inspect and interpret the data. Your group has been working with the Pittsburgh local citizens closely for a long time, and therefore you know the meaning of each variable in the feature set that is used to train the machine learning model. The Pittsburgh community needs your help timely to deliver a report that can help them present evidence of air pollution to the municipality and explain the patterns to the general public. |
Tasks
The individual assignment provided a table for a predefined experiment. In this group assignment, you need to design your own experiment to answer the following question raised by the local Pittsburgh community:
| What are the possible pollution sources that are related to the bad odor in the Pittsburgh region? |
To answer this question, you need to not only select proper variables but also fit the data to the model reasonably well. Consider the following aspects when designing the experiment:
- What are the models that you want to use?
- Hint: use the knowledge that you learned in this module to choose a set of models that you want to investigate. Notice that this is a classification task, and a list of available models can be found at the link below:
- Link to models: https://scikit-learn.org/stable/supervised_learning.html
- What are the variables that you are inteeested in exploring?
- Hint: use the knowledge that you learned in this module to select different sets of variables and check how these sets affect model performance. A list of available variables is mentioned in the tutorial.
- Hint: change the “add_inter” parameter in the code to add interaction terms, such as H2S multiplied by wind direction.
- Hint: use the knowledge that you learned in this module to compute feature importance and inspect which are the important features.
- What is your definition of a smell event (or multiple definitions)?
- Hint: change the “smell_thr” and “smell_predict_hrs” parameters in the code to define smell events. Check the comments in the code for information.
- How many hours do the model need to look back to check the previous data?
- Hint: change the “look_back_hrs” parameter in the code to specify the number of hours that you want the model to look back.
- How much data does the model need to predict bad odor reasonably well?
- Hint: change the “train_size” parameter to increase or decrease the amount of data records for training the machine learning model.
- How often do you need to retrain the model using updated data?
- Hint: change the “test_size” parameter to indicate how often you want to retrain the model with updated data.
When designing the experiment, please consider the computation time carefully. Keep in mind that if you have a very large set of features, training the machine learning model can take a very long time, and explaining the result can also be hard. Instead of doing the experiment with only one set of parameters that produce many features, it may be better to use multiple sets of parameters that produce a smaller number of features. For example, instead of including all the available variables in the experiment, it may be better to separate the variables into several groups, and then train the machine learning model on different groups with different sets of variables.
Deliverable
Your deliverable is the technical report that will be sent to the Pittsburgh local community to help them understand air pollution patterns and advocate for policy changes. Always keep the design brief mentioned above in mind when writing the report. In the report, you need to explain how you completed the above-listed tasks and what the results are.
Specifically and importantly, your report MUST have the following sections, where we will assess your learning outcome based on the grading rubric at the end of this handout. Failing to have these sections will significantly and negatively impact your score.
- Summary
- Provide a summary of what you did and your findings. Maximum 150 words.
- Experiment Design and Implementation
- Describe the machine learning models that you choose and explain why you choose them. The reasons may come from the knowledge that you learned in the lectures or the tutorial.
- Describe the set of features (or multiple sets if you have multiple groups of features) that you choose and why you choose them. The reasons may come from the insights that you learned when you explored the data during the preparation phase of this module.
- Describe how you define the smell events and what motivates you to define the events in this way. You can also have multiple definitions of smell events and conduct experiments using different definitions (i.e., change the “smell_thr” and “smell_predict_hrs” parameters).
- Describe the number of hours that you want the model to look back. You can have multiple settings with different numbers of hours and conduct experiments on all the settings (i.e., change the “look_back_hrs” parameter).
- Describe the amount of data that you use to train your model. You can also have different settings with different numbers of samples and conduct experiments on all the settings (i.e., change the “train_size” parameter).
- Describe how often you think the model needs to be re-trained using updated data. You can have multiple settings with different numbers of the testing set size and conduct experiments on all the settings (i.e., change the “test_size” parameter).
- Explain how you implement the experiment with one or multiple settings using Python code.
- Experiment Results
- Produce one or multiple tables similar to the one provided in the individual assignment to show the results of your experiment. Make sure that you clearly describe what each column in the table means.
- Discussion
- Explain your findings from the experiment. Keep in mind that the local community will read your findings, and they have limited knowledge of machine learning and data science. You need to explain the findings in a way that local citizens and policy-makers can understand.
- For example, from the experiment results, which pollutants are important to predict the presence of poor odor? How do the pollutants travel to the Pittsburgh region? For example, under what conditions of wind directions or speed will the pollutants with bad smell travel to the city region? Remember that you need to use the experiment result to support your argument, for example, the feature importance.
- Also, keep in mind that in the real world, one would need to provide convincing evidence to argue that the machine learning model fits the data reasonably well, for example, using the evaluation metrics mentioned in the tutorial. The findings will not be convincing if the model fits the data poorly, like the dummy classifier (which always predicts “no” smell events) that we used in the tutorial. Smell prediction is a hard task, so do not worry too much about the low performance of the model in this assignment. The assignment aims to let you do experiments and compare the results, not optimize performance.
- Distribution of Group Collaboration
- Describe the distributions of effort in the groups. Make sure that you keep track of this information. It is not acceptable to simply say “all members work together” or “all members contributed equally”. If there are any problems with collaboration, please inform the course coordinator as soon as possible.
In addition, if you read articles (e.g., online blogs, academic papers) and take their ideas, make sure that you cite and attribute the works in your technical report. It is essential to keep this integrity in scientific research.