Tutorial
Table of contents
This section explains the tasks that we will give to you with the guidance of course coaches. In the tutorial session, we will first discuss your findings in the tasks in the “Preparation” section. Next, we will introduce another scenario, where you will use a different set of images to build another application.
| Design brief. Suppose you are working on designing a parking service with the municipality, and you want to build an application to understand the distribution of bikes in cities using image processing techniques. Since the scan cars (as mentioned in the “Preparation” section) take a huge amount of photos, we need a scalable approach to process these photos. |
Task 5
In this task, we will teach you how to automate the image processing pipeline using Python and the Replit online tool https://replit.com. We will give you a script that can process an image using a deployed Hugging Face model. We will guide you through editing the script on Replit to make it work for the bike images that we will provide.
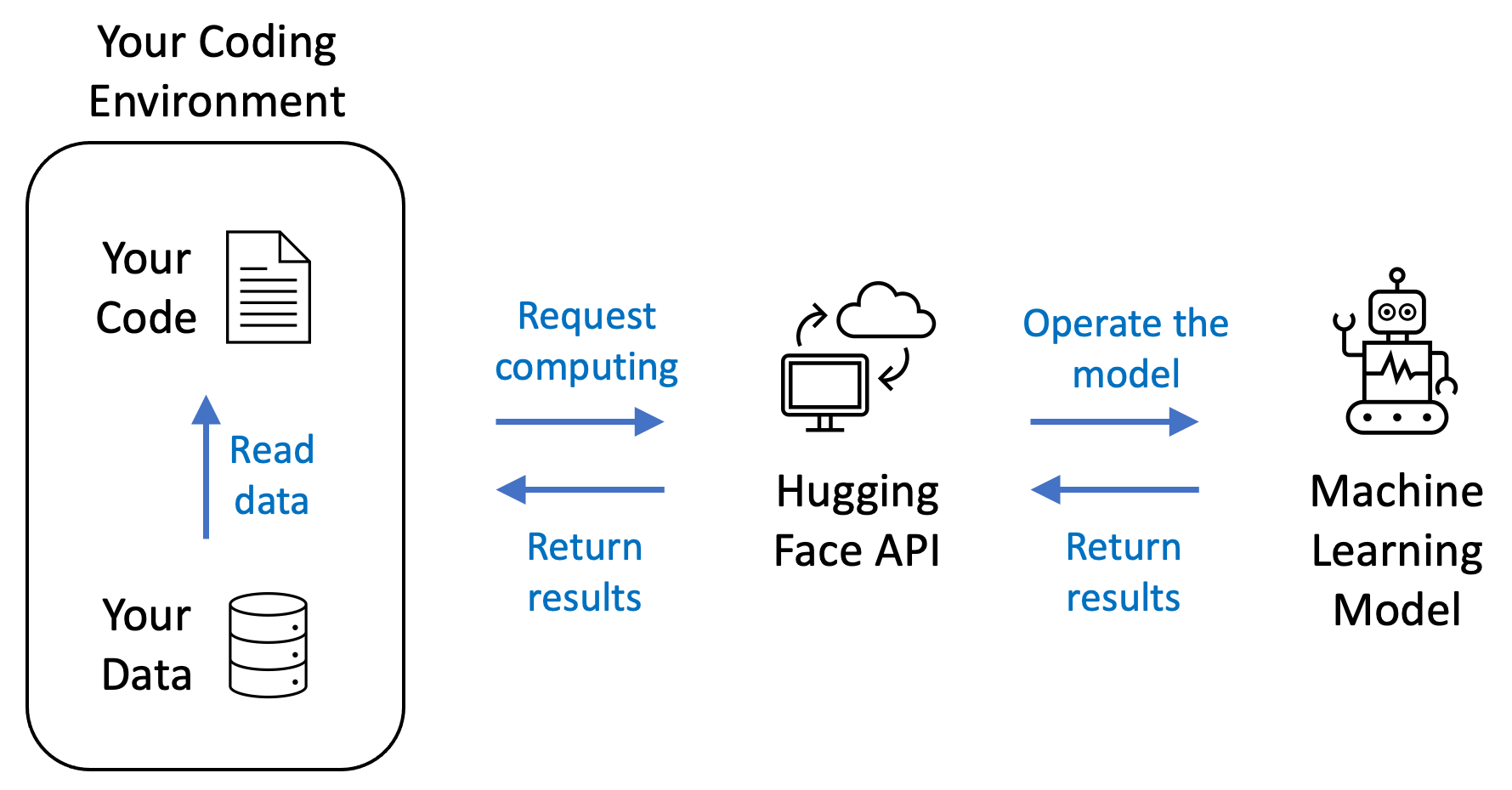
The above figure shows the pipeline. The Python code and the bike image data sit on your coding environment, which is the Replit online tool in our case. Then, when running the code from Replit, the computer that hosts your code will request the Hugging Face API to send and process your data. Once the request is confirmed valid (for example, through the API token), the Hugging Face API will tell a deployed machine learning model to process your data. Finally, the Hugging Face API will collect the results returned by the model and return the results to your coding environment.
First, check the code on Replit. This repl contains the code and images that we want to use in this task. Press the fork button and it will copy the code and images to your own Replit project.
- The code and images can also be found here: https://github.com/aml4design/image-processing-tutorial
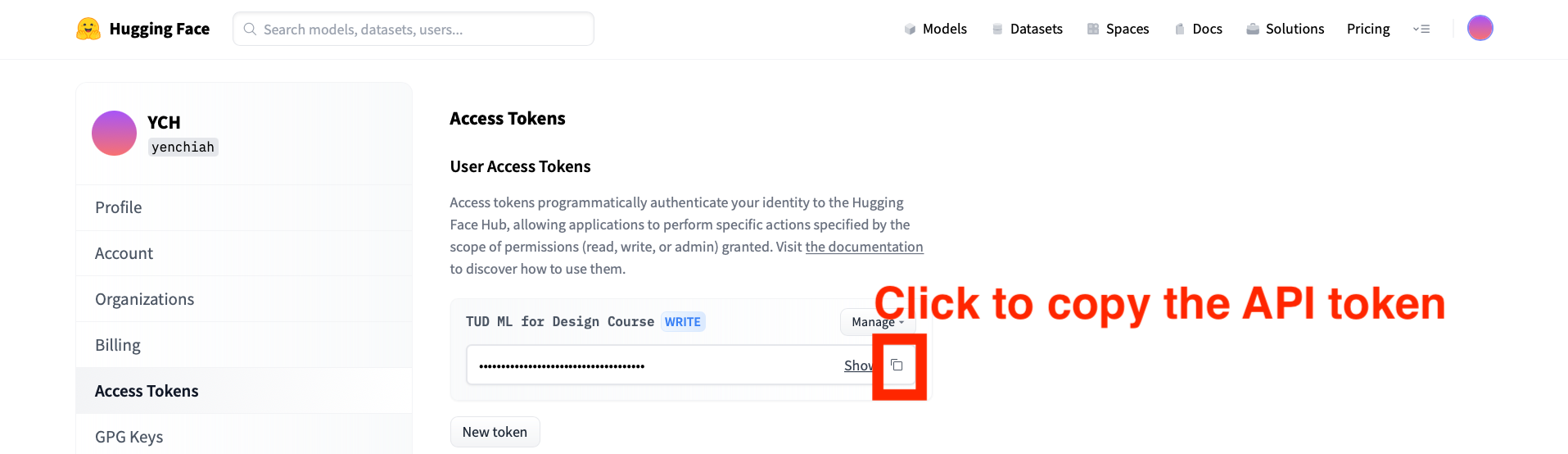
Then, go to the following page to copy your Hugging Face API token. You should already have an API token ready, as indicated in the Preparation section.
- Link to the API token: https://huggingface.co/settings/token
Next, find the following line in the Python script. Replace the [PLACE_HOLDER] part with the copied API token. You need to also replace everything inside the quotation marks.
API_TOKEN = "[PLACE_HOLDER]"
More information about how to use the API can be found in the following page:
After finishing the above steps, click the green “Run” button at the top of the Replit tool to run the script, as shown below:

The tool should begin to install required packages automatically and then give you the following result in the Replit console:
[{'score': 0.9374412894248962, 'label': 'Egyptian cat'}, {'score': 0.03844260051846504,
'label': 'tabby, tabby cat'}, {'score': 0.014411412179470062, 'label': 'tiger cat'},
{'score': 0.003274323185905814, 'label': 'lynx, catamount'}, {'score':
0.0006795919616706669, 'label': 'Siamese cat, Siamese'}]
Seeing the above result means that the code is running correctly. The result is the output from a deployed machine learning model that is specified in the following line in the code:
API_URL = "https://api-inference.huggingface.co/models/google/vit-base-patch16-224"
And the input image is specified in the following line in the code. It is a path that points to an image file, where you uploaded in the “data” folder on Replit.
my_image = "data/000000039769.jpeg"
Here is the image that we just used as the input of the machine learning model:

Now, to explain the output, it is an array of five dictionaries that represent the top 5 predictions from the model. Arrays and dictionaries are both data structures.
- An array looks like [0, 1, 2, 3], which represents a list of elements (such as numbers).
- A dictionary looks like {“key1”: “value1”, “key2”: “value2”}, which represents pairs of keys and values.
In this case, the first element in the array {‘score’: 0.9374412894248962, ‘label’: ‘Egyptian cat’} is the first prediction. It means that the model thinks there are Egyptian cats in the image, with 0.9374412894248962 probability (which is very high).
In the next step, we are going to teach you how to feed the bike images into the model. First, find the following line of code that we mentioned before:
my_image = "data/000000039769.jpeg"
Then, change the path to a bike image, as shown below:
my_image = "data/bike/1/271758547_496887881809012_1375450742634622577_n.jpg"
Here is the bike image for this file path:

Run the model again, and you should see the following output:
[{'score': 0.20871461927890778, 'label': 'mountain bike, all-terrain bike, off-roader'},
{'score': 0.11497228592634201, 'label': 'bicycle-built-for-two, tandem bicycle, tandem'},
{'score': 0.04593493416905403, 'label': 'minibus'}, {'score': 0.026076218113303185,
'label': 'tricycle, trike, velocipede'}, {'score': 0.02415134757757187, 'label':
'jinrikisha, ricksha, rickshaw'}]
Now, try different bike images in the “data/bike” folder and check the output from the model. You can use the web interface (by dragging and dropping images) or the provided code. After that, reflect on the following questions:
- To what extent does this model help understand the distribution of bikes in the city?
- In this task, we have shown how to do image classification, which means giving predictions for the entire image. Are there other ways that you can imagine to help better understand the distribution of bikes in different locations?
Task 6
In the Preparation section and also in the previous task, you have seen image classification, which is a technique to categorize images into multiple types, such as trash bins and bikes. In this task, we will teach you how to use a different model to detect objects in an image, where the model will use bounding boxes to mark the objects to indicate their locations in the image. The difference is that image classification makes predictions for the entire image, while object detection processes multiple parts of the image and gives predictions for each part where an object is identified.
First, go to the following page and use the same bike image that we showed in the previous task as the input of the model.
- Link to the object detection model: https://huggingface.co/facebook/detr-resnet-50
The output should look similar to the screenshot below. Notice that, different from the task that you did before, this model gives bounding boxes with different colors. And each bounding box has a corresponding prediction, such as “bicycle” or “person”.
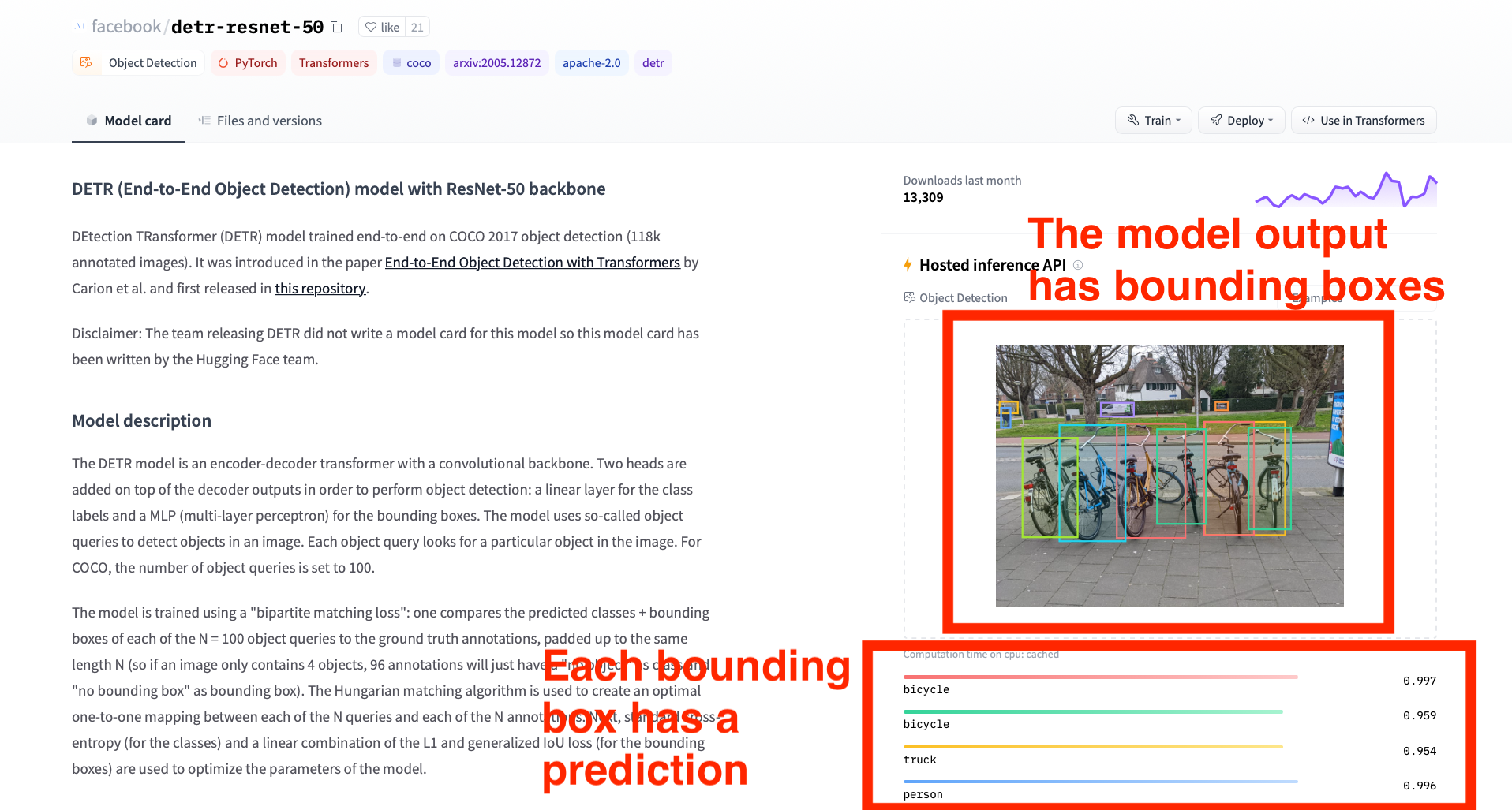
You have interacted with the web interface of the object detection model. Now, we are going to teach you how to change the model to get its output in the Python code on Replit. First, find the following line in the code, which indicates the URL to the model that we used in the previous task.
API_URL = "https://api-inference.huggingface.co/models/google/vit-base-patch16-224"
Next, change the API_URL variable to a different link, as shown below:
API_URL = "https://api-inference.huggingface.co/models/facebook/detr-resnet-50"
Run the code again by clicking on the “Run” button at the top of the Replit interface. The console should print the model output, as shown below:
[{'score': 0.9970716238021851, 'label': 'bicycle', 'box': {'xmin': 333, 'ymin': 216,
'xmax': 522, 'ymax': 531}}, {'score': 0.959046483039856, 'label': 'bicycle', 'box':
{'xmin': 696, 'ymin': 227, 'xmax': 813, 'ymax': 507}}, {'score': 0.9535812735557556,
'label': 'truck', 'box': {'xmin': 10, 'ymin': 155, 'xmax': 60, 'ymax': 187}}, {'score':
0.9961722493171692, 'label': 'person', 'box': {'xmin': 14, 'ymin': 172, 'xmax': 40,
'ymax': 227}}, {'score': 0.9924793243408203, 'label': 'car', 'box': {'xmin': 605, 'ymin':
156, 'xmax': 639, 'ymax': 179}}, {'score': 0.9858757853507996, 'label': 'truck', 'box':
{'xmin': 289, 'ymin': 158, 'xmax': 380, 'ymax': 196}}, {'score': 0.9944808483123779,
'label': 'bicycle', 'box': {'xmin': 175, 'ymin': 220, 'xmax': 357, 'ymax': 540}},
{'score': 0.9925588369369507, 'label': 'bicycle', 'box': {'xmin': 73, 'ymin': 255,
'xmax': 225, 'ymax': 529}}, {'score': 0.9446505904197693, 'label': 'bicycle', 'box':
{'xmin': 574, 'ymin': 211, 'xmax': 711, 'ymax': 523}}, {'score': 0.921903669834137,
'label': 'bicycle', 'box': {'xmin': 444, 'ymin': 231, 'xmax': 579, 'ymax': 492}},
{'score': 0.9477272629737854, 'label': 'bicycle', 'box': {'xmin': 575, 'ymin': 211,
'xmax': 797, 'ymax': 523}}]
The model output is similar to the one that we got before, except that now we get an extra “box” field in the returned data, which means the location of an object in the image. For example, the first item in the array shows that the model predicts a bicycle at the location {‘xmin’: 333, ‘ymin’: 216, ‘xmax’: 522, ‘ymax’: 531} with probability 0.9970716238021851. The numbers in the “box” field mean pixel coordinates, with the top-left point of the image being the origin. So, “xmin” and “ymin” represent the top-left corner of the bounding box, and “xmax” and “ymax” represent the bottom-right corner of the bounding box.